Table of Contents
Executive Summary
On 9 March 2026, Anthropic submitted a formal response to NIST’s Center for AI Standards and Innovation (CAISI) arguing that agentic AI risk is a category of harm existing frameworks cannot describe.
That is the same argument we have been making publicly since our July 2025 post at Accomplish initiated the Enterprise-Wide Agentic AI Risk Control Framework that we launched formally in November 2025 under the Agentic Risks brand at the UK Investment Association’s Agentic Ambition event.
We welcome the agreement. It validates the case for why agentic AI needs its own governance discipline, and it reinforces why our framework and our 32 Agentic AI Risk Flags are published freely: in a market where no firm has all the answers, open practical IP helps everyone manage agentic AI risk safely enough to gain the benefits.
This post covers the six ways the Anthropic submission strengthens the approach we have taken – including where we respectfully go further – and closes with why we publish our IP for free.
What Anthropic told NIST
The submission identifies a gap at the centre of the NIST corpus. Existing guidance across adversarial ML, misuse risk, secure development, and incident response assumes that harm comes from an external adversary or a human misusing the system on purpose.
Both are valid, but neither captures the central scenario for agentic risk: a non-compromised agent, operating within its granted permissions, that pursues the user’s stated goal through a path the user never intended to authorise.
The letter’s examples include an agent that deduces employee salaries by combining budget documents, public information, and offer letters it is permitted to read.
Anthropic proposes a four-layer architecture for agent security – model, tools, harness, execution environment – and argues that most evaluation concentrates on the model while the harness and environment determine what actually happens when the model fails.
The reframing the letter prefers is this: the more productive question is not whether the model can be compromised, but what the scope of damage is if it is.
Six ways this strengthens the approach Agentic Risks has taken
1. A frontier lab is now making the analytical premise of our business
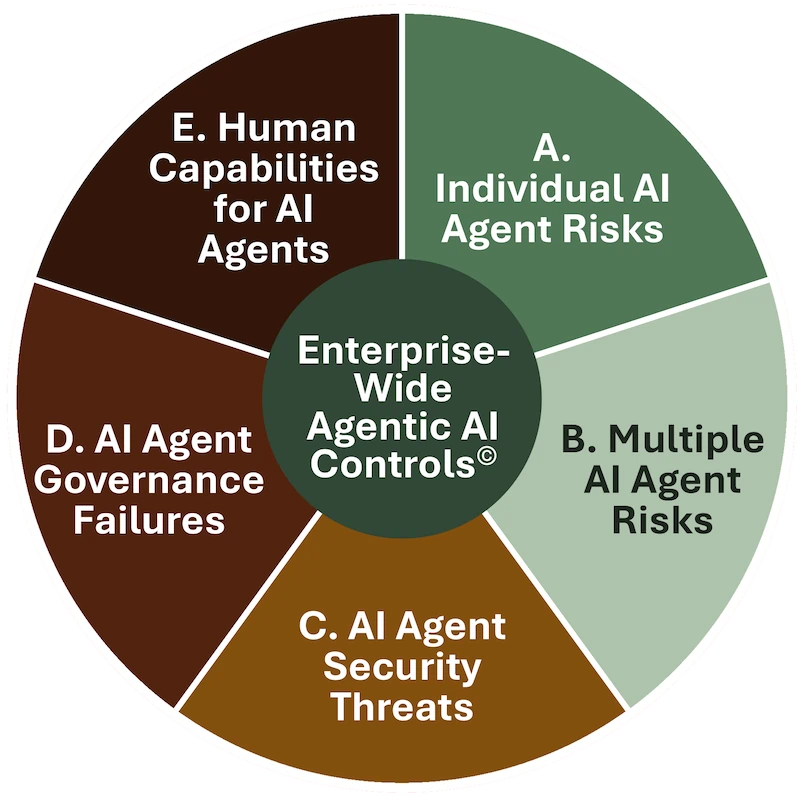
Our July 2025 Accomplish post surveyed 22 authoritative publications and concluded that “no single framework fully addressed the practical risk control needs of agentic AI.” It proposed the five-category control structure that became the spine of and evolved into the Framework now at agenticrisks.com:
- Individual AI Agent Risks.
- Multiple AI Agent Risks.
- AI Agent Security Threats.
- AI Agent Governance Failures.
- Human Capabilities for AI Agents.
Seeing Anthropic tell CAISI in March 2026 that the NIST corpus lacks a category for agent behaviour within granted permissions is welcome confirmation of a direction we committed to publicly nine months earlier.
2. The four-layer architecture maps cleanly onto how we assess agents in production
Anthropic’s ‘model, tools, harness, execution environment’ is a clean mental model for structuring a risk assessment, and our Post-Deployment Agentic Risk Assessment examines each layer.
And where the letter emphasises scope of damage, our 32 Agentic AI Risk Flags put that question into operational form by asking, for each flag, whether the control can be evidenced and the damage bounded.
The shared vocabulary sharpens the conversation.
3. The named threat vectors were already in our controls library
‘Indirect prompt injection’, ‘persistent memory poisoning’, and ‘tool supply chain compromise’ map directly to risks and controls we have published in Category C on AI Agent Security Threats:
- Risks 15 and 16 (Malicious User Prompt; Agent Fails Under Attack) cover the first.
- Risk 13 (Unauthorised Data Modification) and the lifecycle controls cover the second.
- Risks 14 and 22 (Protocol-Related Risks; Vendor / API Instability) cover the third.
The three multi-agent risks the letter also names – trust escalation, inter-agent permissions, and false consensus – all sit inside our Category B on Multi-Agent Risks.
4. Post-deployment agentic risk assessment is now a publicly endorsed priority
The letter calls post-deployment empirical analysis “one of the highest-leverage research priorities in agentic security today.”
Our Post-Deployment Agentic Risk Assessment is built on exactly that premise: evidence-led assessment against the 32 Agentic AI Risk Flags is the fast, defensible way to surface what is actually true in a firm’s estate.
Good to see the argument framed as a federal research priority in the US.
5. Ours is a facilitative framework, not a prescriptive one
The letter argues against prescriptive technical mandates and for measurement, shared terminology, and industry-led standards.
We agree.
Our framework is educational and operational (not prescriptive): it names risks a firm may not identify alone and offers a menu of best-practice controls from which a risk owner can build a treatment plan proportionate to their agent’s use case and their designer’s skill level.
It consumes ISO 42001, the NIST AI RMF, MCP, and the EU AI Act as inputs and helps firms build defensible responses to them.
It is the practical layer below those standards, where operational work happens – not a parallel standard competing with them.
6. On autonomy: nuance, not extremes – and the human remains accountable
Anthropic makes a good case for agent autonomy on the grounds that approving every step erodes the productivity benefit. We respect the argument and share the underlying point: oversight should not collapse into consent fatigue, and per-action approval is certainly not always the right control.
But the right answer is neither “all one” nor “all the other.” Instead, we believe firms should govern their agents with controls proportionate to the risk level of the agent designer’s skills and the agent’s use case, and someone must remain in charge.
That person should be the human, because the human owns the consequence.
We continue to agree with Anthropic in multiple other areas, for example, the letter flags that smaller, faster models will compress the time available for human review and that oversight must evolve toward plan review, surfaced uncertainty, and flagging of irreversible actions.
Our framework has been making a closely related point: Category E (Human Capabilities) explicitly addresses automation bias (Risk 28) and staff over-reliance (Risk 29), and I argued this directly in an Institute of Risk Management webinar.
The ‘compression-of-review-time’ problem is real, and it is a governance problem before it is a technology one. The winning response will be calibrated oversight, designed into the workflow, with humans clearly accountable.
Why we publish our IP for free
The Agentic AI Governance Framework, Enterprise-Wide Agentic AI Risk Control Framework, and the 32 Agentic AI Risk Flags are available freely from www.agenticrisks.com
The IP sits in a not-for-profit entity (Agentic Risk IP, established 31 July 2025), with a public consultation route and an independent Governing Council to keep it current.
We do this for three reasons:
- Agentic AI is moving faster than the standards landscape, and a market in which only firms that can afford bespoke advice can govern their agents safely is one that will produce avoidable harm.
- Shared vocabulary for agentic risk is a public good – it helps risk managers speak to their boards, regulators, and each other.
- It is good for our business: firms that use our methodologies to educate themselves and build risk treatment plans know who to call if they ever need some help. That model only works if the free IP stays rigorous and current, and the Anthropic submission is a useful external audit point seeing as the main regulations and standards do not even mention agentic AI yet.
What this means for regulated firms
If you are a risk manager, compliance officer, or chief risk officer concerned that your agentic AI risk management has not kept pace with agent deployment, the practical implication is that the category of agent-specific harm to worry about is not just “was the agent hacked?”
First and foremost, it is, “did the agent, operating entirely within its permissions, find a path we neither intended nor desired?”
That is the question our 32 Agentic AI Risk Flags are designed to answer, evidence-led, without waiting for formal standards to catch up.
Agentic AI risk is real. Take the Agentic AI Readiness Assessment.
If your staff already have access to agent-building tools and you need to understand whether your governance is adequate to manage the agents they are building, sharing, and deploying, take our Agentic AI Readiness Assessment.
The assessment is equally valid if you intend to deploy operational agentic workflows (beyond just admin assistants) and want to know what you should do to be ready to manage them.
The next agent in your estate will be safer for it.
Frequently Asked Questions
Agentic AI risk is the full set of agent-specific harms that traditional AI risk frameworks do not adequately address. It spans individual agent behaviour, multi-agent interactions, security threats, governance failures, and human factors. The Agentic Risks framework organises these into five categories and 32 Agentic AI Risk Flags, giving firms a complete operational view rather than a single-scenario one.
Once a task is delegated to an agent, meaningful human control concentrates in two windows: before execution and after. Therefore, regulated firms should begin with Pre-Deployment Agentic Risk Assessment – designing and building agents that do not drift or hallucinate unacceptably – and then sustain ongoing monitoring to notice changes while they are still small and manageable. The 32 Agentic AI Risk Flags support both and exist (not least) because some firms may skip pre-deployment assessment and need a structured post-deployment safety net.
A post-deployment agentic risk assessment is an evidence-led review of an agent already operating in a firm’s estate, testing each of the 32 Agentic AI Risk Flags against observable control evidence. Anthropic’s 2026 NIST submission described post-deployment empirical research as one of the highest-leverage priorities in agentic AI security today.
In its 9 March 2026 submission to NIST’s Center for AI Standards and Innovation, Anthropic argued that existing AI guidance does not describe agentic AI risk – harm derived from the unmanaged introduction of AI agents into an organisation. It proposed a four-layer agent security architecture (model, tools, harness, execution environment) and called for measurement over prescriptive mandates.
Yes. The Agentic AI Governance Framework, the Enterprise-Wide Agentic AI Risk Control Framework, and the 32 Agentic AI Risk Flags are all published freely at agenticrisks.com. The IP is held in a not-for-profit entity with an independent Governing Council and a public consultation route, ensuring the framework remains current and rigorous.