
Table of Contents
Executive Summary
Agentic workflows are not “just another AI model” – they are operational systems that can act, spend, and escalate at speed.
That means risk is shaped as much by design choices (ownership, boundaries, monitoring, and stop authority) as by the task the agent performs.
If you, as a risk manager, are asked to perform an agentic AI risk assessment, you will need a fast, defensible way to determine whether the project is sufficiently controllable to go live.
This practical guide gives you 32 verifiable agentic AI risk flags you can test with evidence, so you can quickly translate findings into clear, proportionate risk treatment plans.
Agentic AI Risk Assessment for Agentic Workflows
An agentic AI risk assessment is an evidence-led review of whether an agentic workflow can be owned, constrained, monitored, and safely stopped before production.
For a new agentic workflow, risk managers should be involved from the design phase to help technologists control the end-to-end process.
This is because an agentic workflow is much more than just an agent; it includes agent-human hand-offs, tool usage and costs, staff training and oversight, vendor dependencies, incident management, and potentially external disclosures.
Without this involvement, the gap between an impressive prototype and a successful operational process can become a chasm.
But what if it does not happen that way? What if, as the risk manager, the project team only engages you after they have designed and trained the agent? Or after they have completed testing and want to go live?
How can you orient yourself and add value quickly while simultaneously protecting yourself from the disadvantages of late involvement?

De-risk your agentic transformation
As agentic workflows become more common, risk managers may increasingly find themselves in this situation, and a low-risk task is not the same as a low-risk agent (see Methodology).
Succeeding requires three things: structure to identify risks, depth to verify controls, and speed to produce recommendations.
Those who are ready will strengthen their professional credibility and help their organisations secure the benefits: productivity uplifts, greater consistency and quality, and faster decision support.
Risk Flags for an Agentic Workflow
To help risk managers run an agentic AI risk assessment quickly, Agentic Risks has summarised the controls in the Enterprise-Wide Agentic AI Risk Control Framework into 32 verifiable agentic AI risk flags.
Fundamentally, they change the risk conversation from, “Could this go wrong?” to, “Demonstrate how this is under control.”
Each flag is designed to surface evidence a risk team can request and verify that vital controls are in place. For example: audit logs, access controls, monitoring outputs, approval records, change tickets, incident procedures, and operational dashboards.
The flags also map back to the Framework’s categories, risks, controls, and (in Q1 2026), common types of evidence, so you can trace what you observed to what should exist and translate findings into a proportionate risk treatment plan.
We are currently testing the evidence library and, by the end of Q1 2026, you will be able to download the full spreadsheet version for free with flag descriptions, potential impacts, and control references. This should enable fast, consistent and defensible risk assessments – see the example below.
To use the flags, review each one and request the minimum evidence to confirm it is absent. Record the outcomes as Controlled, Flag present, or Unknown (evidence missing).
If you are asking how to assess an agentic workflow, start with ownership and stop authority first, then move to monitoring, approval points, security boundaries, and only then performance. In practice, weak governance creates more risk than weak model accuracy.
Your output should be a risk report that lists which flags are present, what evidence is missing, the likely impact if unresolved, and the recommended control actions (or risk acceptance decisions).
If you cannot identify ownership, constrain behaviour, or stop the agent safely, you do not have an acceptable control position and you should consider recommending delaying go-live until evidence is available.
You can also use the flags as a lightweight agentic AI governance checklist for go-live decisions, internal audit readiness, and risk committee sign-off.
See also:
| Flag # | Agentic Risk Flag |
| A. Individual AI Agent Risks – an agent may act unpredictably or unfairly, drift from intent, or operate outside policy, causing errors, bias, or inconsistent outcomes. | |
| 1. | No clear human accountability across the agent’s full lifecycle. |
| 2. | Agent reached production without formal control points. |
| 3. | Objectives, risk appetite, and constraints cannot be traced to code-level controls. |
| 4. | No machine-enforced least-privilege on tool and data access. |
| 5. | Limits, safeguards, and risk controls were added after training or deployment. |
| 6. | Behaviour changes occur without a controlled release or update. |
| B. Multiple AI Agent Risks – agents may interact, replicate, or conflict in ways that undermine oversight, stability, and accountability. | |
| 7. | Agent or component identity cannot be uniquely identified or authenticated. |
| 8. | Multi-agent coordination was not tested before agents were allowed to collaborate. |
| 9. | No real-time constraint validation on chained actions. |
| 10. | Replication occurs without governance control. |
| C. AI Agent Security Threats – agents and their data pipelines may be attacked or misused, enabling unsafe behaviour, data exposure, or loss of control. | |
| 11. | Unauthorised data access or modification cannot be reliably contained. |
| 12. | Malicious inputs could execute with real privileges. |
| 13. | Compromised state could persist after detection. |
| D. AI Agent Governance Failures – weak accountability and oversight can cause outages, compliance breaches, cost overruns, and reputational damage. | |
| 14. | External dependencies are unknown or unmanaged. |
| 15. | No authoritative view of live and retired agents. |
| 16. | Agent decisions cannot be reconstructed. |
| 17. | Kill-switch or stop authority untested. |
| 18. | No defined human approval points for agent actions with real-world impact. |
| 19. | Compliance knowledge is fragmented or undocumented. |
| 20. | Monitoring is periodic or static. |
| 21. | Monitoring focuses only on agent performance. |
| 22. | Claims about an agent are not traceable or provable. |
| 23. | Governance and oversight are not a priority. |
| E. Human Capabilities for AI Agents – insufficient training, inadequate risk and change management, misuse, or over-trust can stall adoption and weaken operational control. | |
| 24. | “Big-bang” deployment with no non-AI rollback. |
| 25. | Informal agentic workflow design. |
| 26. | Platform chosen before control requirements identified. |
| 27. | No risk assessment of an agent's potential behavioural choices. |
| 28. | Adversarial testing did not take place. |
| 29. | Staff training and change support happens after an agent is deployed. |
| 30. | Users cannot evidence why agent decisions were made or accepted. |
| 31. | No evidence that staff challenge AI-generated outputs. |
| 32. | No proactive impact assessment on human rights for agent-driven decisions. |
Example: Flag #1
Because risks interact, each flag maps to multiple risks. Here’s Flag #1:
- Agentic Flag #1: no clear human accountability across the agent’s full lifecycle.
- Description: the agent has no single accountable owner who will authorise its design, testing, deployment, operation, update, escalation, and shutdown. As the agent moves through lifecycle stages, ownership may be fragmented, implied rather than explicit, unclear, or disputed.
- Potential Impact: without clear ownership, intervention during an incident may be delayed or disputed, allowing harmful or unsafe behaviour to persist; risk of regulatory escalation.
- Control Framework References:
- Risk 01: Agent Lifecycle Management.
- Risk 06: Agent Identity Confusion or Exploitation.
- Risk 07: Overlapping or Conflicting Agent Actions.
- Risk 09: Uncontrolled Agent Replication.
- Risk 22: Accountability, Explainability, and Monitoring.
- Risk 24: Regulatory Risk.
- Risk Treatment Plan: as the risk manager, you will be able to target your application of the Framework by drilling-through into the references and constructing a risk treatment plan from the appropriate controls, which you can then discuss with your colleagues. In practice, a proportionate risk treatment plan usually falls into one of four options: 1) reduce agent autonomy, 2) add control points and monitoring, 3) redesign the workflow to reintroduce safe human hand-offs, or 4) delay go-live until evidence of control is available.
In many organisations, unresolved accountability gaps eventually surface as a failure to manage AI agent accountability, human approval points, or a tested kill switch when behaviour becomes unsafe.
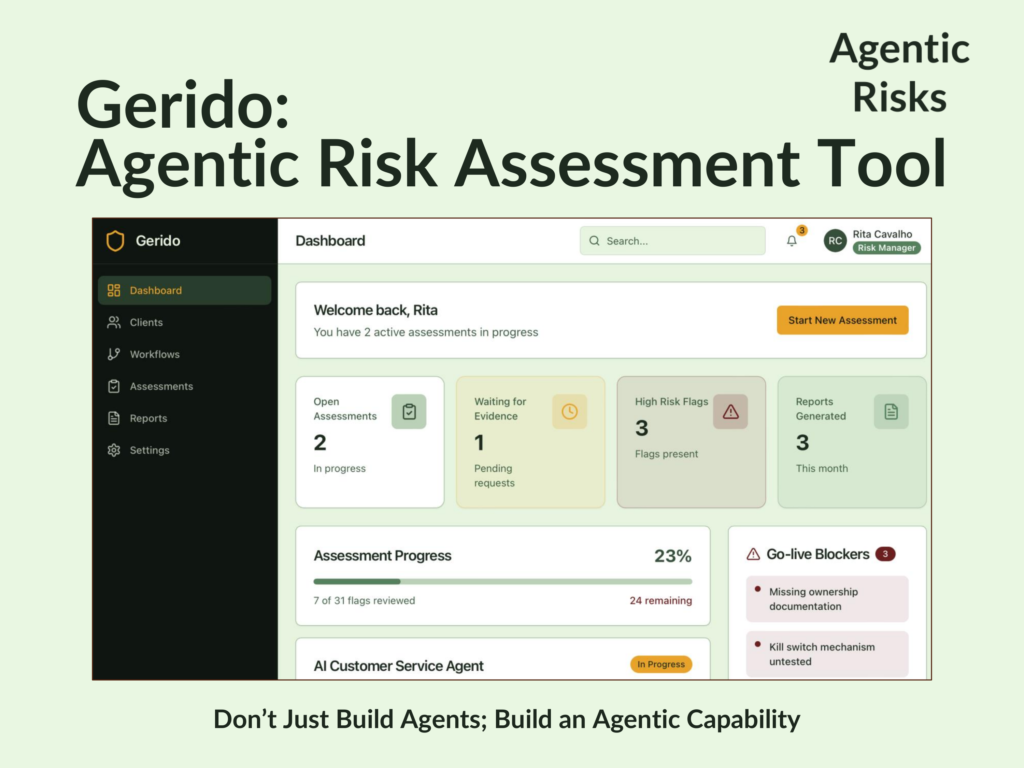
Ways to Leverage the Agentic AI Risk Flags
With these flags, if you are engaged early to perform an agentic AI risk assessment, you can now prevent foreseeable oversights by making risk expectations explicit. And if you are engaged later, you can now focus immediately on the highest-impact risks and produce defensible findings fast.
If you want support conducting an agentic risk assessment, we can either upskill your team with practical training, or work alongside you to complete an assessment quickly and defensibly.
- Training Workshop – if concepts like prompt injection and agentic autonomy are new for your team, we’ll give them the skills to identify risk flags, test for evidence of controls, and translate findings into clear recommendations.
- Independent Risk Assessment – if your risk function is stretched, or you need an assessment delivered before training can be scheduled, we can perform the assessment with your team using our proprietary agentic workflows risk assessment software (Gerido).
If you want to operationalise the flags quickly, we can help you select the right assessment approach, align it to your governance model, and produce a defensible set of findings your stakeholders can act on.
Methodology
If an agent is performing well on a relatively low-risk task but you cannot constrain, track, or stop it, it is not a low-risk agent – it is a high-risk agent that is currently occupied on a low-risk task.
But small errors can compound, either changing its activity volumes (raising a high cost risk), pushing on its boundaries (a high scope risk), or leaving an attack surface undefended (a high security risk).
As a result, whether an agent is high-risk relates as much to the strength of its controls as to the task it has been given.
To reflect this, the primary filters focus on evidence of identity, ownership, boundaries, safety, explainability, and stop authority.
Secondary filters related to ensuring the agent effectively completes its approved task, that staff know how to use and oversee it, and that change teams know how to redesign end-to-end procedures into agentic workflows, in which humans and agents collaborate.
The result is a set of verifiable risk flags rooted in a comprehensive agentic control framework. This lets you:
- Evidence the controls that prevent each risk flag.
- Justify why it does not apply (consistent with the ISO 42001’s ‘statement of applicability’).
- Construct an appropriate risk treatment plan (consistent with the NIST AI RMF’s governance / measurement expectations).
Put simply: the flags help you build a clear “show me the evidence” assessment that stands up to internal audit, regulators, and incident review.
FAQs
A risk flag is a high-signal indicator that controls may be missing or ineffective. Controls are the specific measures that prevent or mitigate the issue. The flags help you find control gaps quickly and prioritise what to fix first.

