Table of Contents
Executive Summary
Once you deploy autonomous agents that can fail in ways that non-agentic alerting was not designed to detect, only incident management for agentic AI will protect you if something goes wrong.
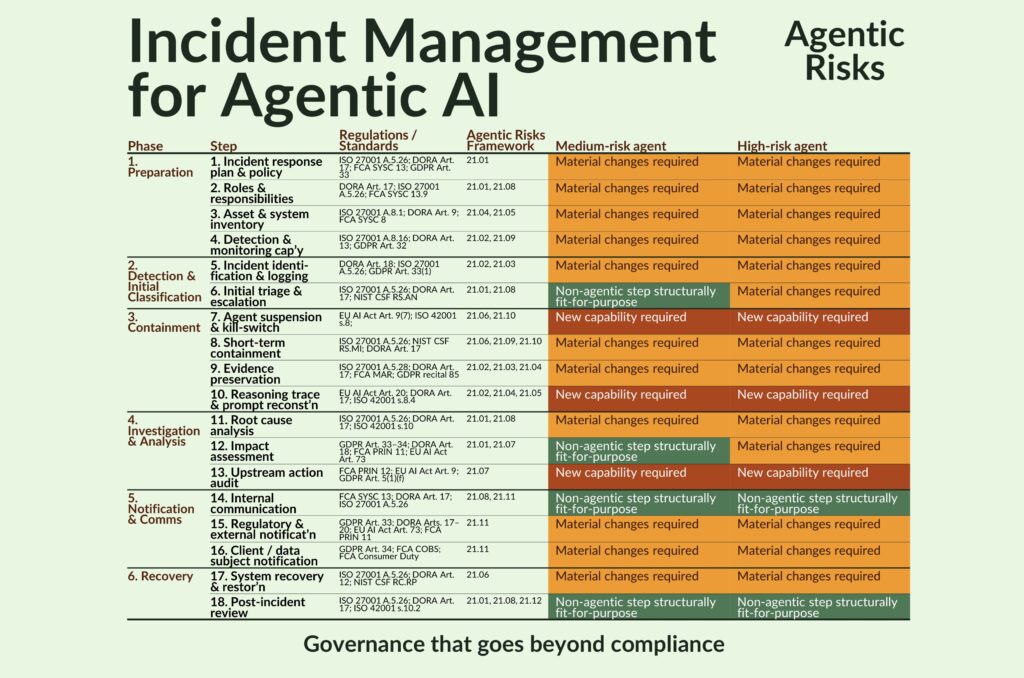
Of the 18 steps needed to manage an agentic incident, only 2 survive intact – 3 have no non-agentic equivalent at all, and 13 require material changes – creating operational and regulatory exposure for firms that have already deployed agents.
The most effective response plan is to diagnose your gaps, define bespoke upgrades that match your agentic use cases, and sequence implementation to ensure they support other in-flight initiatives.
Our three-stage Agentic Incident Management Upgrade service is designed to achieve exactly this for you.

Incident Management Has an Agentic Blind Spot
Could your firm have a blind spot to its need for incident management for agentic AI?
Incident management procedures were built for predictable failure scenarios: systems go down, data is breached, users make mistakes. These are events the procedure was designed around – the triggers are known, the response steps are defined, and the evidence trail is familiar.
However, agentic AI introduces a fundamentally different operational resilience problem – agents can fail gradually with no single point of failure, across multiple systems, within their permitted boundaries, and in ways that non-agentic alerting was not designed to detect.
When a firm deploys a medium or high-risk AI agent, it introduces a new category of operational risk, with failure modes that are materially different from the scenarios for which non-agentic incident management was built.
Incidents from autonomous AI systems can be gradual, cross-system, and invisible to non-agentic alert mechanisms – leaving your detection, containment, and evidence capabilities configured for predictable failures when they will need to respond to unpredictable ones.
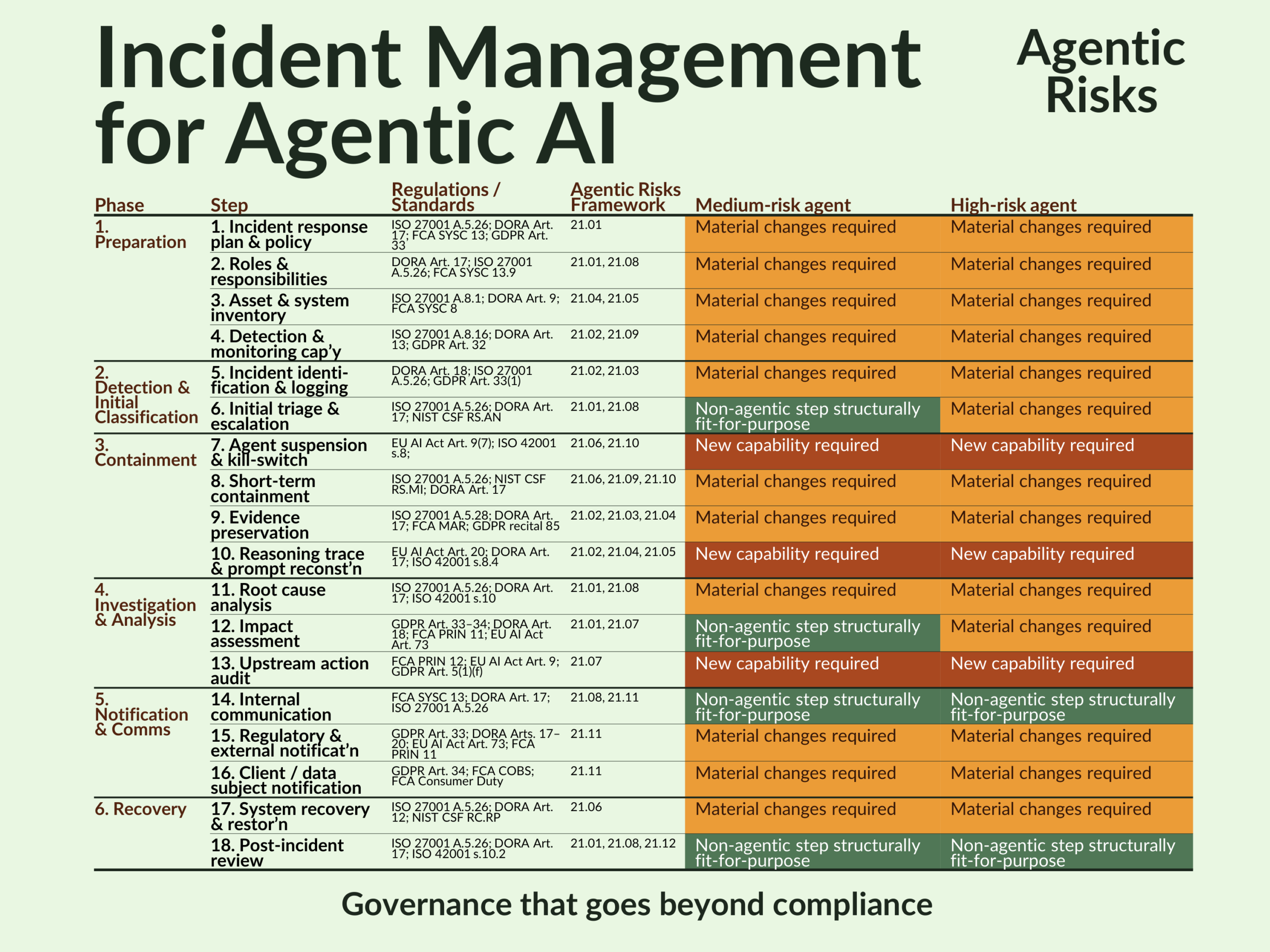
A Heat Map of the Required Changes
For the reasons above, a non-agentic incident management procedure will not protect you in an agentic environment. The heat map shows why.
In our analysis, we used the following risk definitions:
- Medium-risk agent – an internal workflow, accessing business data, performing independent reasoning for human approval on final decision, e.g. investment research, lead qualification, or invoice processing.
- High-risk agent – as above, plus access to external systems and data and the presence of multi-agent orchestration, e.g. trade execution, client comms, or regulatory reporting.
Our key findings were that of the 18 steps needed to manage an agentic incident, 3 (in red) have no non-agentic equivalent, 11 (amber) require material changes to scope, tooling, or evidence requirements, 4 (green) require no change for medium-risk agents and only 2 survive intact for high-risk agents.
If your firm has deployed agents before upgrading its incident management procedure, you may be exposed from a regulatory as well as an operational perspective, with EU AI Act obligations for high-risk AI systems arriving and DORA incident management obligations already in force.

Why Preparation Will Matter
To understand what is at stake, consider this scenario.
An asset manager deploys an execution agent to manage portfolio rebalancing. The agent receives an instruction from an upstream portfolio analytics agent. The instruction is ambiguous – not wrong, not outside permissions, just unclear. The execution agent interprets it as authorisation to rebalance a client portfolio. It executes 14 trades across three venues. Each individual action falls within the agent’s permission boundaries.
Three days later, a portfolio manager notices the positions do not match the investment mandate. By then, the trades have settled. The evidence window for reconstructing the agent’s reasoning trace has closed because no logging infrastructure was in place to capture it. And the firm is now working out how to explain to its regulator why a DORA-notifiable event went undetected for 72 hours.
The failure – autonomous action, within permissions, across a multi-agent chain, invisible to non-agentic monitoring – is a plausible scenario and a structural property of how these systems work. It is also the specific risk Anthropic raised when it announced its belief that agentic AI risk is a distinct category of harm that existing frameworks do not describe.
The firms that will handle this well are those whose procedures were ready before the incident occurred:
- Detection configured for agentic behaviour.
- A kill-switch that did not require a developer to invoke it.
- Logging infrastructure that captured the reasoning trace.
- A notification decision tree that mapped the DORA and EU AI Act pathways before anyone had to figure them out under pressure.
The firms that will struggle are those who did not upgrade their procedures to detect an autonomous, cross-system failure. They will likely spend more time on the incident, lose more evidence, face a harder regulatory conversation, and be slower to resume normal operation.
The difference between those two outcomes is procedure, not technical capability.
Incident Management for Agentic AI: What Good Looks Like
Risk 21 of the Enterprise-Wide Agentic AI Risk Control Framework defines the controls a well-governed organisation should have in place for agentic incident management – from comprehensive AI agent forensic logging and immutable evidence retention through to downstream action audit and user diagnostic collaboration.
To upgrade your incident management procedure for agentic AI, you will need to evolve what you already have, updating what needs updating, adding what is missing, and leaving intact what already works.
What makes this different from a non-agentic procedure review is that three of the steps have no non-agentic equivalent, yet you will need them – at no notice – when an agentic incident occurs:
- A tested AI agent kill-switch mechanism that can be invoked without developer involvement.
- Structured logging of AI reasoning traces and prompt versions that supports post-incident reconstruction.
- A downstream action audit methodology that identifies every autonomous system action the agent took before containment was achieved.
Together, the framework defines what good looks like, while the upgraded procedure operationalises it and provides a defensible basis under regulatory scrutiny.

Three Obstacles and How to Overcome Them
While the case for upgrading your incident management for agentic AI is straightforward, the journey to get there may not be. Specifically, you will need to navigate three obstacles:
1. A Blind Spot to the Gaps
Without a structured assessment, the temptation will be to rely on guesswork or to assume the existing procedure is a safe baseline, when it may not be.
To counteract this, your starting point should be a systematic review of the maturity of your firm’s current procedure against all 18 steps, scored against four maturity levels.
2. Upgrade Requirements Must Be Bespoke
A firm running medium-risk agents has a different set of requirements from one running high-risk agents with live external system access. Use cases also matter, with the same technology creating materially different risk exposure depending on the activity performed.
As a result, a one-size-fits-all checklist will not produce the right procedure for any firm.
Instead, upgrades need to be defined against your firm’s actual agent estate, scoped to its risk tier, and calibrated to its specific regulatory obligations.
3. Implementation Sequencing
Introducing the Agentic Incident Management Upgrade Service
For these reasons, we deliberately designed our Agentic Incident Management Upgrade service so that its three stages address each obstacle in turn:
- Stage 1 is a diagnostic that produces a scored maturity assessment and gap analysis – a standalone deliverable with its own regulatory evidence value, whether or not the firm proceeds further. If you have the internal resource to take it from here, the engagement need go no further.
- Stage 2 defines your firm’s specific upgrade requirements, scoped to its agent risk tier and regulatory obligations.
- Stage 3 sequences the implementation work into a prioritised project plan, with in-flight initiative dependencies identified and coordinated.
If you are deploying medium or high-risk agents and have not reviewed your incident management procedure against these 18 steps, formalising your gap analysis should be a priority.
To get started, book a free 30-minute consultation to discuss where your procedure stands and what a structured upgrade would involve.
Frequently Asked Questions
Traditional incident management was designed for predictable failures like outages, breaches, and user error. Autonomous AI agents introduce unpredictable, cross-system, and gradual failure modes that conventional alerting, evidence collection, and containment procedures were not designed to detect or investigate.
Conventional monitoring tools are typically designed to detect system outages, threshold breaches, or predefined anomalies. Agentic AI incidents may occur within authorised permissions, across multiple systems, and without triggering traditional alerts, making behavioural monitoring and reasoning-trace logging essential.
An AI agent kill-switch is a control mechanism that allows an organisation to rapidly suspend or isolate an AI agent without requiring developer intervention. It is designed to support containment during an agentic incident before additional autonomous actions occur.
Forensic logging supports post-incident reconstruction by capturing reasoning traces, prompt versions, tool usage, and downstream actions. Without this evidence, firms may struggle to investigate autonomous decisions, demonstrate governance, or meet regulatory expectations.
DORA requires firms to identify, manage, record, classify, and report ICT-related incidents. Where agentic AI systems can trigger operational disruption, firms may need incident management procedures capable of detecting, evidencing, and escalating autonomous failures within regulatory reporting timelines.
Reasoning traces are structured records showing how an AI agent reached a decision, including prompts, intermediate reasoning steps, tool calls, and outputs. They support explainability, forensic analysis, and post-incident investigation.
Yes. High-risk AI agents typically require stronger controls because they may access external systems, orchestrate other agents, or execute actions autonomously. Examples include autonomous action containment controls, enhanced forensic logging and evidence retention, and cross-system incident correlation and escalation. Incident management procedures should therefore be calibrated to the agent’s operational scope, autonomy, and regulatory exposure.